Architecture
Exzo Cluster
A Exzo cluster is a set of validators working together to serve client transactions and maintain the integrity of the ledger. Many clusters may coexist. When two clusters share a common genesis block, they attempt to converge. Otherwise, they simply ignore the existence of the other. Transactions sent to the wrong one are quietly rejected. In this section, we'll discuss how a cluster is created, how nodes join the cluster, how they share the ledger, how they ensure the ledger is replicated, and how they cope with buggy and malicious nodes.
Creating a Cluster
Before starting any validators, one first needs to create a genesis config. The config references two public keys, a mint and a bootstrap validator. The validator holding the bootstrap validator's private key is responsible for appending the first entries to the ledger. It initializes its internal state with the mint's account. That account will hold the number of native tokens defined by the genesis config. The second validator then contacts the bootstrap validator to register as a validator. Additional validators then register with any registered member of the cluster.
A validator receives all entries from the leader and submits votes confirming those entries are valid. After voting, the validator is expected to store those entries. Once the validator observes a sufficient number of copies exist, it deletes its copy.
Joining a Cluster
Validators enter the cluster via registration messages sent to its control plane. The control plane is implemented using a gossip protocol, meaning that a node may register with any existing node, and expect its registration to propagate to all nodes in the cluster. The time it takes for all nodes to synchronize is proportional to the square of the number of nodes participating in the cluster. Algorithmically, that's considered very slow, but in exchange for that time, a node is assured that it eventually has all the same information as every other node, and that that information cannot be censored by any one node.
Sending Transactions to a Cluster
Clients send transactions to any validator's Transaction Processing Unit (TPU) port. If the node is in the validator role, it forwards the transaction to the designated leader. If in the leader role, the node bundles incoming transactions, timestamps them creating an entry, and pushes them onto the cluster's data plane. Once on the data plane, the transactions are validated by validator nodes, effectively appending them to the ledger.
Confirming Transactions
A Exzo cluster is capable of subsecond confirmation for up to 150 nodes with plans to scale up to hundreds of thousands of nodes. Once fully implemented, confirmation times are expected to increase only with the logarithm of the number of validators, where the logarithm's base is very high. If the base is one thousand, for example, it means that for the first thousand nodes, confirmation will be the duration of three network hops plus the time it takes the slowest validator of a supermajority to vote. For the next million nodes, confirmation increases by only one network hop.
Exzo defines confirmation as the duration of time from when the leader timestamps a new entry to the moment when it recognizes a supermajority of ledger votes.
A gossip network is much too slow to achieve subsecond confirmation once the network grows beyond a certain size. The time it takes to send messages to all nodes is proportional to the square of the number of nodes. If a blockchain wants to achieve low confirmation and attempts to do it using a gossip network, it will be forced to centralize to just a handful of nodes.
Scalable confirmation can be achieved using the follow combination of techniques:
Timestamp transactions with a VDF sample and sign the timestamp.
Split the transactions into batches, send each to separate nodes and have
each node share its batch with its peers.
Repeat the previous step recursively until all nodes have all batches.
Exzo rotates leaders at fixed intervals, called slots. Each leader may only produce entries during its allotted slot. The leader therefore timestamps transactions so that validators may lookup the public key of the designated leader. The leader then signs the timestamp so that a validator may verify the signature, proving the signer is owner of the designated leader's public key.
Next, transactions are broken into batches so that a node can send transactions to multiple parties without making multiple copies. If, for example, the leader needed to send 60 transactions to 6 nodes, it would break that collection of 60 into batches of 10 transactions and send one to each node. This allows the leader to put 60 transactions on the wire, not 60 transactions for each node. Each node then shares its batch with its peers. Once the node has collected all 6 batches, it reconstructs the original set of 60 transactions.
A batch of transactions can only be split so many times before it is so small that header information becomes the primary consumer of network bandwidth. At the time of this writing, the approach is scaling well up to about 150 validators. To scale up to hundreds of thousands of validators, each node can apply the same technique as the leader node to another set of nodes of equal size. We call the technique Turbine Block Propagation.
Synchronization
Fast, reliable synchronization is the biggest reason why we've chosen Solana for achieving high throughput. Traditional blockchains synchronize on large chunks of transactions called blocks. By synchronizing on blocks, a transaction cannot be processed until a duration, called "block time", has passed. In Proof of Work consensus, these block times need to be very large (~10 minutes) to minimize the odds of multiple validators producing a new valid block at the same time. There's no such constraint in Proof of Stake consensus, but without reliable timestamps, a validator cannot determine the order of incoming blocks. The popular workaround is to tag each block with a wallclock timestamp. Because of clock drift and variance in network latencies, the timestamp is only accurate within an hour or two. To workaround the workaround, these systems lengthen block times to provide reasonable certainty that the median timestamp on each block is always increasing.
Solana takes a very different approach, which it calls Proof of History or PoH. Leader nodes "timestamp" blocks with cryptographic proofs that some duration of time has passed since the last proof. All data hashed into the proof most certainly have occurred before the proof was generated. The node then shares the new block with validator nodes, which are able to verify those proofs. The blocks can arrive at validators in any order or even could be replayed years later. With such reliable synchronization guarantees, Solana is able to break blocks into smaller batches of transactions called entries. Entries are streamed to validators in realtime, before any notion of block consensus.
Solana technically never sends a block, but uses the term to describe the sequence of entries that validators vote on to achieve confirmation. In that way, Solana's confirmation times can be compared apples to apples to block-based systems. The current implementation sets block time to 800ms.
What's happening under the hood is that entries are streamed to validators as quickly as a leader node can batch a set of valid transactions into an entry. Validators process those entries long before it is time to vote on their validity. By processing the transactions optimistically, there is effectively no delay between the time the last entry is received and the time when the node can vote. In the event consensus is not achieved, a node simply rolls back its state. This optimisic processing technique was introduced in 1981 and called Optimistic Concurrency Control. It can be applied to blockchain architecture where a cluster votes on a hash that represents the full ledger up to some block height. In Solana, it is implemented trivially using the last entry's PoH hash.
Relationship to VDFs
The Proof of History technique was first described for use in blockchain by Solana in November of 2017. In June of the following year, a similar technique was described at Stanford and called a verifiable delay function or VDF.
A desirable property of a VDF is that verification time is very fast. Solana's approach to verifying its delay function is proportional to the time it took to create it. Split over a 4000 core GPU, it is sufficiently fast for Solana's needs, but if you asked the authors of the paper cited above, they might tell you (and have) that Solana's approach is algorithmically slow and it shouldn't be called a VDF. We argue the term VDF should represent the category of verifiable delay functions and not just the subset with certain performance characteristics. Until that's resolved, Solana will likely continue using the term PoH for its application-specific VDF.
Another difference between PoH and VDFs is that a VDF is used only for tracking duration. PoH's hash chain, on the other hand, includes hashes of any data the application observed. That data is a double-edged sword. On one side, the data "proves history" - that the data most certainly existed before hashes after it. On the other side, it means the application can manipulate the hash chain by changing when the data is hashed. The PoH chain therefore does not serve as a good source of randomness whereas a VDF without that data could. Solana's leader rotation algorithm, for example, is derived only from the VDF height and not its hash at that height.
Relationship to Consensus Mechanisms
Proof of History is not a consensus mechanism, but it is used to improve the performance of Solana's Proof of Stake consensus. It is also used to improve the performance of the data plane protocols.
Leader Rotation
At any given moment, a cluster expects only one validator to produce ledger entries. By having only one leader at a time, all validators are able to replay identical copies of the ledger. The drawback of only one leader at a time, however, is that a malicious leader is capable of censoring votes and transactions. Since censoring cannot be distinguished from the network dropping packets, the cluster cannot simply elect a single node to hold the leader role indefinitely. Instead, the cluster minimizes the influence of a malicious leader by rotating which node takes the lead.
Each validator selects the expected leader using the same algorithm, described below. When the validator receives a new signed ledger entry, it can be certain that an entry was produced by the expected leader. The order of slots which each leader is assigned a slot is called a leader schedule.
Leader Schedule Rotation
A validator rejects blocks that are not signed by the slot leader. The list of identities of all slot leaders is called a leader schedule. The leader schedule is recomputed locally and periodically. It assigns slot leaders for a duration of time called an epoch. The schedule must be computed far in advance of the slots it assigns, such that the ledger state it uses to compute the schedule is finalized. That duration is called the leader schedule offset. Exzo sets the offset to the duration of slots until the next epoch. That is, the leader schedule for an epoch is calculated from the ledger state at the start of the previous epoch. The offset of one epoch is fairly arbitrary and assumed to be sufficiently long such that all validators will have finalized their ledger state before the next schedule is generated. A cluster may choose to shorten the offset to reduce the time between stake changes and leader schedule updates.
While operating without partitions lasting longer than an epoch, the schedule only needs to be generated when the root fork crosses the epoch boundary. Since the schedule is for the next epoch, any new stakes committed to the root fork will not be active until the next epoch. The block used for generating the leader schedule is the first block to cross the epoch boundary.
Without a partition lasting longer than an epoch, the cluster will work as follows:
A validator continuously updates its own root fork as it votes.
The validator updates its leader schedule each time the slot height crosses an epoch boundary.
For example:
The epoch duration is 100 slots. The root fork is updated from fork computed at slot height 99 to a fork computed at slot height 102. Forks with slots at height 100, 101 were skipped because of failures. The new leader schedule is computed using fork at slot height 102. It is active from slot 200 until it is updated again.
No inconsistency can exist because every validator that is voting with the cluster has skipped 100 and 101 when its root passes 102. All validators, regardless of voting pattern, would be committing to a root that is either 102, or a descendant of 102.
Leader Schedule Rotation with Epoch Sized Partitions.
The duration of the leader schedule offset has a direct relationship to the likelihood of a cluster having an inconsistent view of the correct leader schedule.
Consider the following scenario:
Two partitions that are generating half of the blocks each. Neither is coming to a definitive supermajority fork. Both will cross epoch 100 and 200 without actually committing to a root and therefore a cluster-wide commitment to a new leader schedule.
In this unstable scenario, multiple valid leader schedules exist.
A leader schedule is generated for every fork whose direct parent is in the previous epoch.
The leader schedule is valid after the start of the next epoch for descendant forks until it is updated.
Each partition's schedule will diverge after the partition lasts more than an epoch. For this reason, the epoch duration should be selected to be much much larger then slot time and the expected length for a fork to be committed to root.
After observing the cluster for a sufficient amount of time, the leader schedule offset can be selected based on the median partition duration and its standard deviation. For example, an offset longer then the median partition duration plus six standard deviations would reduce the likelihood of an inconsistent ledger schedule in the cluster to 1 in 1 million.
Leader Schedule Generation at Genesis
The genesis config declares the first leader for the first epoch. This leader ends up scheduled for the first two epochs because the leader schedule is also generated at slot 0 for the next epoch. The length of the first two epochs can be specified in the genesis config as well. The minimum length of the first epochs must be greater than or equal to the maximum rollback depth as defined in Tower BFT.
Leader Schedule Generation Algorithm
Leader schedule is generated using a predefined seed. The process is as follows:
Periodically use the PoH tick height (a monotonically increasing counter) to seed a stable pseudo-random algorithm.
At that height, sample the bank for all the staked accounts with leader identities that have voted within a cluster-configured number of ticks. The sample is called the active set.
Sort the active set by stake weight.
Use the random seed to select nodes weighted by stake to create a stake-weighted ordering.
This ordering becomes valid after a cluster-configured number of ticks.
Schedule Attack Vectors
Seed
The seed that is selected is predictable but unbiasable. There is no grinding attack to influence its outcome.
Active Set
A leader can bias the active set by censoring validator votes. Two possible ways exist for leaders to censor the active set:
Ignore votes from validators
Refuse to vote for blocks with votes from validators
To reduce the likelihood of censorship, the active set is calculated at the leader schedule offset boundary over an active set sampling duration. The active set sampling duration is long enough such that votes will have been collected by multiple leaders.
Delegating
Leaders can censor new delegation transactions or refuse to validate blocks with new delegations. This attack is similar to censorship of validator votes.
Validator operational key loss
Leaders and validators are expected to use ephemeral keys for operation, and stake owners authorize the validators to do work with their stake via delegation.
The cluster should be able to recover from the loss of all the ephemeral keys used by leaders and validators, which could occur through a common software vulnerability shared by all the nodes. Stake owners should be able to vote directly by co-signing a validator vote even though the stake is currently delegated to a validator.
Appending Entries
The lifetime of a leader schedule is called an epoch. The epoch is split into slots, where each slot has a duration of T PoH ticks.
A leader transmits entries during its slot. After T ticks, all the validators switch to the next scheduled leader. Validators must ignore entries sent outside a leader's assigned slot.
All T ticks must be observed by the next leader for it to build its own entries on. If entries are not observed (leader is down) or entries are invalid (leader is buggy or malicious), the next leader must produce ticks to fill the previous leader's slot. Note that the next leader should do repair requests in parallel, and postpone sending ticks until it is confident other validators also failed to observe the previous leader's entries. If a leader incorrectly builds on its own ticks, the leader following it must replace all its ticks.
Fork Generation
Fork Generation
This section describes how forks naturally occur as a consequence of leader rotation.
Overview
Nodes take turns being leader and generating the PoH that encodes state changes. The cluster can tolerate loss of connection to any leader by synthesizing what the leader would have generated had it been connected but not ingesting any state changes. The possible number of forks is thereby limited to a "there/not-there" skip list of forks that may arise on leader rotation slot boundaries. At any given slot, only a single leader's transactions will be accepted.
Message Flow
- Transactions are ingested by the current leader.
- Leader filters valid transactions.
- Leader executes valid transactions updating its state.
- Leader packages transactions into entries based off its current PoH slot.
- Leader transmits the entries to validator nodes (in signed shreds)
- The PoH stream includes ticks; empty entries that indicate liveness of the leader and the passage of time on the cluster.
- A leader's stream begins with the tick entries necessary to complete PoH back to the leader's most recently observed prior leader slot.
- Validators retransmit entries to peers in their set and to further downstream nodes.
- Validators validate the transactions and execute them on their state.
- Validators compute the hash of the state.
- At specific times, i.e. specific PoH tick counts, validators transmit votes to the leader.
- Votes are signatures of the hash of the computed state at that PoH tick count.
- Votes are also propagated via gossip.
- Leader executes the votes, the same as any other transaction, and broadcasts them to the cluster.
- Validators observe their votes and all the votes from the cluster.
Partitions, Forks
Forks can arise at PoH tick counts that correspond to a vote. The next leader may not have observed the last vote slot and may start their slot with generated virtual PoH entries. These empty ticks are generated by all nodes in the cluster at a cluster-configured rate for hashes/per/tick Z.
There are only two possible versions of the PoH during a voting slot: PoH with T ticks and entries generated by the current leader, or PoH with just ticks. The "just ticks" version of the PoH can be thought of as a virtual ledger, one that all nodes in the cluster can derive from the last tick in the previous slot.
Validators can ignore forks at other points (e.g. from the wrong leader), or slash the leader responsible for the fork.
Validators vote based on a greedy choice to maximize their reward described in Tower BFT.
Validator's View
Time Progression
The diagram below represents a validator's view of the PoH stream with possible forks over time. L1, L2, etc. are leader slots, and Es represent entries from that leader during that leader's slot. The xs represent ticks only, and time flows downwards in the diagram.
Note that an E appearing on 2 forks at the same slot is a slashable condition, so a validator observing E3 and E3' can slash L3 and safely choose x for that slot. Once a validator commits to a fork, other forks can be discarded below that tick count. For any slot, validators need only consider a single "has entries" chain or a "ticks only" chain to be proposed by a leader. But multiple virtual entries may overlap as they link back to the previous slot.
Time Division
It's useful to consider leader rotation over PoH tick count as time division of the job of encoding state for the cluster. The following table presents the above tree of forks as a time-divided ledger.
leader slot | L1 | L2 | L3 | L4 | L5 |
data | E1 | E2 | E3 | E4 | E5 |
ticks since prev | L1 | L2 | L3 | x | xx |
Note that only data from leader L3 will be accepted during leader slot L3. Data from L3 may include "catchup" ticks back to a slot other than L2 if L3 did not observe L2's data. L4 and L5's transmissions include the "ticks to prev" PoH entries.
This arrangement of the network data streams permits nodes to save exactly this to the ledger for replay, restart, and checkpoints.
Leader's View
When a new leader begins a slot, it must first transmit any PoH (ticks) required to link the new slot with the most recently observed and voted slot. The fork the leader proposes would link the current slot to a previous fork that the leader has voted on with virtual ticks.
Managing Forks
Managing Forks
The ledger is permitted to fork at slot boundaries. The resulting data structure forms a tree called a blockstore. When the validator interprets the blockstore, it must maintain state for each fork in the chain. We call each instance an active fork. It is the responsibility of a validator to weigh those forks, such that it may eventually select a fork.
A validator selects a fork by submiting a vote to a slot leader on that fork. The vote commits the validator for a duration of time called a lockout period. The validator is not permitted to vote on a different fork until that lockout period expires. Each subsequent vote on the same fork doubles the length of the lockout period. After some cluster-configured number of votes (currently 32), the length of the lockout period reaches what's called max lockout. Until the max lockout is reached, the validator has the option to wait until the lockout period is over and then vote on another fork. When it votes on another fork, it performs an operation called rollback, whereby the state rolls back in time to a shared checkpoint and then jumps forward to the tip of the fork that it just voted on. The maximum distance that a fork may roll back is called the rollback depth. Rollback depth is the number of votes required to achieve max lockout. Whenever a validator votes, any checkpoints beyond the rollback depth become unreachable. That is, there is no scenario in which the validator will need to roll back beyond rollback depth. It therefore may safely prune unreachable forks and squash all checkpoints beyond rollback depth into the root checkpoint.
Active Forks
An active fork is as a sequence of checkpoints that has a length at least one longer than the rollback depth. The shortest fork will have a length exactly one longer than the rollback depth. For example:
The following sequences are active forks:
- 1
- 1
- 1
- 1
Pruning and Squashing
A validator may vote on any checkpoint in the tree. In the diagram above, that's every node except the leaves of the tree. After voting, the validator prunes nodes that fork from a distance farther than the rollback depth and then takes the opportunity to minimize its memory usage by squashing any nodes it can into the root.
Starting from the example above, with a rollback depth of 2, consider a vote on 5 versus a vote on 6. First, a vote on 5:
The new root is 2, and any active forks that are not descendants from 2 are pruned.
Alternatively, a vote on 6:
The tree remains with a root of 1, since the active fork starting at 6 is only 2 checkpoints from the root.
Turbine Block Propagation
Turbine Block Propagation
An Exzo Network cluster uses a multi-layer block propagation mechanism called Turbine to broadcast transaction shreds to all nodes with minimal amount of duplicate messages. The cluster divides itself into small collections of nodes, called neighborhoods. Each node is responsible for sharing any data it receives with the other nodes in its neighborhood, as well as propagating the data on to a small set of nodes in other neighborhoods. This way each node only has to communicate with a small number of nodes.
During its slot, the leader node distributes shreds between the validator nodes in the first neighborhood (layer 0). Each validator shares its data within its neighborhood, but also retransmits the shreds to one node in some neighborhoods in the next layer (layer 1). The layer-1 nodes each share their data with their neighborhood peers, and retransmit to nodes in the next layer, etc, until all nodes in the cluster have received all the shreds.
Neighborhood Assignment - Weighted Selection
In order for data plane fanout to work, the entire cluster must agree on how the cluster is divided into neighborhoods. To achieve this, all the recognized validator nodes (the TVU peers) are sorted by stake and stored in a list. This list is then indexed in different ways to figure out neighborhood boundaries and retransmit peers. For example, the leader will simply select the first nodes to make up layer 0. These will automatically be the highest stake holders, allowing the heaviest votes to come back to the leader first. Layer 0 and lower-layer nodes use the same logic to find their neighbors and next layer peers.
To reduce the possibility of attack vectors, each shred is transmitted over a random tree of neighborhoods. Each node uses the same set of nodes representing the cluster. A random tree is generated from the set for each shred using a seed derived from the leader id, slot and shred index.
Layer and Neighborhood Structure
The current leader makes its initial broadcasts to at most DATA_PLANE_FANOUT nodes. If this layer 0 is smaller than the number of nodes in the cluster, then the data plane fanout mechanism adds layers below. Subsequent layers follow these constraints to determine layer-capacity: Each neighborhood contains DATA_PLANE_FANOUT nodes. Layer 0 starts with 1 neighborhood with fanout nodes. The number of nodes in each additional layer grows by a factor of fanout.
As mentioned above, each node in a layer only has to broadcast its shreds to its neighbors and to exactly 1 node in some next-layer neighborhoods, instead of to every TVU peer in the cluster. A good way to think about this is, layer 0 starts with 1 neighborhood with fanout nodes, layer 1 adds fanout neighborhoods, each with fanout nodes and layer 2 will have fanout * number of nodes in layer 1 and so on.
This way each node only has to communicate with a maximum of 2 * DATA_PLANE_FANOUT - 1 nodes.
The following diagram shows how the Leader sends shreds with a fanout of 2 to Neighborhood 0 in Layer 0 and how the nodes in Neighborhood 0 share their data with each other.
The following diagram shows how Neighborhood 0 fans out to Neighborhoods 1 and 2.
Finally, the following diagram shows a two layer cluster with a fanout of 2.
Configuration Values
DATA_PLANE_FANOUT - Determines the size of layer 0. Subsequent layers grow by a factor of DATA_PLANE_FANOUT. The number of nodes in a neighborhood is equal to the fanout value. Neighborhoods will fill to capacity before new ones are added, i.e if a neighborhood isn't full, it must be the last one.
Currently, configuration is set when the cluster is launched. In the future, these parameters may be hosted on-chain, allowing modification on the fly as the cluster sizes change.
Calculating the required FEC rate
Turbine relies on retransmission of packets between validators. Due to retransmission, any network wide packet loss is compounded, and the probability of the packet failing to reach its destination increases on each hop. The FEC rate needs to take into account the network wide packet loss, and the propagation depth.
A shred group is the set of data and coding packets that can be used to reconstruct each other. Each shred group has a chance of failure, based on the likelyhood of the number of packets failing that exceeds the FEC rate. If a validator fails to reconstruct the shred group, then the block cannot be reconstructed, and the validator has to rely on repair to fixup the blocks.
The probability of the shred group failing can be computed using the binomial distribution. If the FEC rate is 16:4, then the group size is 20, and at least 4 of the shreds must fail for the group to fail. Which is equal to the sum of the probability of 4 or more trails failing out of 20.
Probability of a block succeeding in turbine:
- Probability of packet failure: P = 1 - (1 - network_packet_loss_rate)^2
- FEC rate: K:M
- Number of trials: N = K + M
- Shred group failure rate: S = SUM of i=0 -> M for binomial(prob_failure = P, trials = N, failures = i)
- Shreds per block: G
- Block success rate: B = (1 - S) ^ (G / N)
- Binomial distribution for exactly i results with probability of P in N trials is defined as (N choose i) _ P^i _ (1 - P)^(N-i)
For example:
- Network packet loss rate is 15%.
- 50k tps network generates 6400 shreds per second.
- FEC rate increases the total shreds per block by the FEC ratio.
With a FEC rate: 16:4
- G = 8000
- P = 1 - 0.85 * 0.85 = 1 - 0.7225 = 0.2775
- S = SUM of i=0 -> 4 for binomial(prob_failure = 0.2775, trials = 20, failures = i) = 0.689414
- B = (1 - 0.689) ^ (8000 / 20) = 10^-203
With FEC rate of 16:16
- G = 12800
- S = SUM of i=0 -> 32 for binomial(prob_failure = 0.2775, trials = 64, failures = i) = 0.002132
- B = (1 - 0.002132) ^ (12800 / 32) = 0.42583
With FEC rate of 32:32
- G = 12800
- S = SUM of i=0 -> 32 for binomial(prob_failure = 0.2775, trials = 64, failures = i) = 0.000048
- B = (1 - 0.000048) ^ (12800 / 64) = 0.99045
Neighborhoods
The following diagram shows how two neighborhoods in different layers interact. To cripple a neighborhood, enough nodes (erasure codes +1) from the neighborhood above need to fail. Since each neighborhood receives shreds from multiple nodes in a neighborhood in the upper layer, we'd need a big network failure in the upper layers to end up with incomplete data.
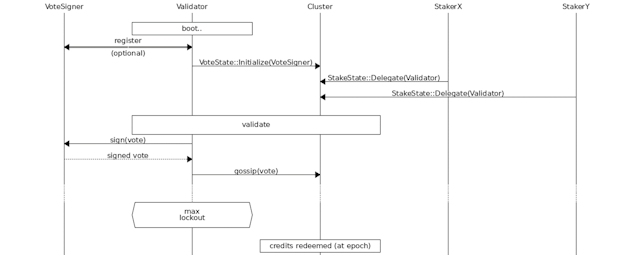
Secure Vote Signing
Secure Vote Signing
A validator receives entries from the current leader and submits votes confirming those entries are valid. This vote submission presents a security challenge, because forged votes that violate consensus rules could be used to slash the validator's stake.
The validator votes on its chosen fork by submitting a transaction that uses an asymmetric key to sign the result of its validation work. Other entities can verify this signature using the validator's public key. If the validator's key is used to sign incorrect data (e.g. votes on multiple forks of the ledger), the node's stake or its resources could be compromised.
Exzo Network addresses this risk by splitting off a separate vote signer service that evaluates each vote to ensure it does not violate a slashing condition.
Validators, Vote Signers, and Stakeholders
When a validator receives multiple blocks for the same slot, it tracks all possible forks until it can determine a "best" one. A validator selects the best fork by submitting a vote to it, using a vote signer to minimize the possibility of its vote inadvertently violating a consensus rule and getting a stake slashed.
A vote signer evaluates the vote proposed by the validator and signs the vote only if it does not violate a slashing condition. A vote signer only needs to maintain minimal state regarding the votes it signed and the votes signed by the rest of the cluster. It doesn't need to process a full set of transactions.
A stakeholder is an identity that has control of the staked capital. The stakeholder can delegate its stake to the vote signer. Once a stake is delegated, the vote signer's votes represent the voting weight of all the delegated stakes, and produce rewards for all the delegated stakes.
Currently, there is a 1:1 relationship between validators and vote signers, and stakeholders delegate their entire stake to a single vote signer.
Signing service
The vote signing service consists of a JSON RPC server and a request processor. At startup, the service starts the RPC server at a configured port and waits for validator requests. It expects the following type of requests:
- Register a new validator node
- The request must contain validator's identity (public key)
- The request must be signed with the validator's private key
- The service drops the request if signature of the request cannot be verified
- The service creates a new voting asymmetric key for the validator, and returns the public key as a response
- If a validator tries to register again, the service returns the public key from the pre-existing keypair
- Sign a vote
- The request must contain a voting transaction and all verification data
- The request must be signed with the validator's private key
- The service drops the request if signature of the request cannot be verified
- The service verifies the voting data
- The service returns a signature for the transaction
Validator voting
A validator node, at startup, creates a new vote account and registers it with the cluster by submitting a new "vote register" transaction. The other nodes on the cluster process this transaction and include the new validator in the active set. Subsequently, the validator submits a "new vote" transaction signed with the validator's voting private key on each voting event.
Configuration
The validator node is configured with the signing service's network endpoint (IP/Port).
Registration
At startup, the validator registers itself with its signing service using JSON RPC. The RPC call returns the voting public key for the validator node. The validator creates a new "vote register" transaction including this public key, and submits it to the cluster.
Vote Collection
The validator looks up the votes submitted by all the nodes in the cluster for the last voting period. This information is submitted to the signing service with a new vote signing request.
New Vote Signing
The validator creates a "new vote" transaction and sends it to the signing service using JSON RPC. The RPC request also includes the vote verification data. On success, the RPC call returns the signature for the vote. On failure, RPC call returns the failure code.
Stake Delegation and Rewards
Stake Delegation and Rewards
Stakers are rewarded for helping to validate the ledger. They do this by delegating their stake to validator nodes. Those validators do the legwork of replaying the ledger and sending votes to a per-node vote account to which stakers can delegate their stakes. The rest of the cluster uses those stake-weighted votes to select a block when forks arise. Both the validator and staker need some economic incentive to play their part. The validator needs to be compensated for its hardware and the staker needs to be compensated for the risk of getting its stake slashed. The economics are covered in staking rewards. This section, on the other hand, describes the underlying mechanics of its implementation.
Basic Design
The general idea is that the validator owns a Vote account. The Vote account tracks validator votes, counts validator generated credits, and provides any additional validator specific state. The Vote account is not aware of any stakes delegated to it and has no staking weight.
A separate Stake account (created by a staker) names a Vote account to which the stake is delegated. Rewards generated are proportional to the amount of lamports staked. The Stake account is owned by the staker only. Some portion of the lamports stored in this account are the stake.
Passive Delegation
Any number of Stake accounts can delegate to a single Vote account without an interactive action from the identity controlling the Vote account or submitting votes to the account.
The total stake allocated to a Vote account can be calculated by the sum of all the Stake accounts that have the Vote account pubkey as the StakeState::Stake::voter_pubkey.
Vote and Stake accounts
The rewards process is split into two on-chain programs. The Vote program solves the problem of making stakes slashable. The Stake program acts as custodian of the rewards pool and provides for passive delegation. The Stake program is responsible for paying rewards to staker and voter when shown that a staker's delegate has participated in validating the ledger.
VoteState
VoteState is the current state of all the votes the validator has submitted to the network. VoteState contains the following state information:
- votes - The submitted votes data structure.
- credits - The total number of rewards this Vote program has generated over its lifetime.
- root_slot - The last slot to reach the full lockout commitment necessary for rewards.
- commission - The commission taken by this VoteState for any rewards claimed by staker's Stake accounts. This is the percentage ceiling of the reward.
- Account::lamports - The accumulated lamports from the commission. These do not count as stakes.
- authorized_voter - Only this identity is authorized to submit votes. This field can only modified by this identity.
- node_pubkey - The Exzo Network node that votes in this account.
- authorized_withdrawer - the identity of the entity in charge of the lamports of this account, separate from the account's address and the authorized vote signer.
VoteInstruction::Initialize(VoteInit)
- account[0] - RW - The VoteState.
VoteInit carries the new vote account's node_pubkey, authorized_voter, authorized_withdrawer, and commission.
other VoteState members defaulted.
VoteInstruction::Authorize(Pubkey, VoteAuthorize)
Updates the account with a new authorized voter or withdrawer, according to the VoteAuthorize parameter (Voter or Withdrawer). The transaction must be signed by the Vote account's current authorized_voter or authorized_withdrawer.
- account[0] - RW - The VoteState. VoteState::authorized_voter or authorized_withdrawer is set to Pubkey.
VoteInstruction::Vote(Vote)
- account[0] - RW - The VoteState. VoteState::lockouts and VoteState::credits are updated according to voting lockout rules see Tower BFT.
- account[1] - RO - sysvar::slot_hashes A list of some N most recent slots and their hashes for the vote to be verified against.
- account[2] - RO - sysvar::clock The current network time, expressed in slots, epochs.
StakeState
A StakeState takes one of four forms, StakeState::Uninitialized, StakeState::Initialized, StakeState::Stake, and StakeState::RewardsPool. Only the first three forms are used in staking, but only StakeState::Stake is interesting. All RewardsPools are created at genesis.
StakeState::Stake
StakeState::Stake is the current delegation preference of the staker and contains the following state information:
- Account::lamports - The lamports available for staking.
- stake - the staked amount (subject to warmup and cooldown) for generating rewards, always less than or equal to Account::lamports.
- voter_pubkey - The pubkey of the VoteState instance the lamports are delegated to.
- credits_observed - The total credits claimed over the lifetime of the program.
- activated - the epoch at which this stake was activated/delegated. The full stake will be counted after warmup.
- deactivated - the epoch at which this stake was de-activated, some cooldown epochs are required before the account is fully deactivated, and the stake available for withdrawal.
- authorized_staker - the pubkey of the entity that must sign delegation, activation, and deactivation transactions.
- authorized_withdrawer - the identity of the entity in charge of the lamports of this account, separate from the account's address, and the authorized staker.
StakeState::RewardsPool
To avoid a single network-wide lock or contention in redemption, 256 RewardsPools are part of genesis under pre-determined keys, each with std::u64::MAX credits to be able to satisfy redemptions according to point value.
The Stakes and the RewardsPool are accounts that are owned by the same Stake program.
StakeInstruction::DelegateStake
The Stake account is moved from Initialized to StakeState::Stake form, or from a deactivated (i.e. fully cooled-down) StakeState::Stake to activated StakeState::Stake. This is how stakers choose the vote account and validator node to which their stake account lamports are delegated. The transaction must be signed by the stake's authorized_staker.
- account[0] - RW - The StakeState::Stake instance. StakeState::Stake::credits_observed is initialized to VoteState::credits, StakeState::Stake::voter_pubkey is initialized to account[1]. If this is the initial delegation of stake, StakeState::Stake::stake is initialized to the account's balance in lamports, StakeState::Stake::activated is initialized to the current Bank epoch, and StakeState::Stake::deactivated is initialized to std::u64::MAX
- account[1] - R - The VoteState instance.
- account[2] - R - sysvar::clock account, carries information about current Bank epoch.
- account[3] - R - sysvar::stakehistory account, carries information about stake history.
- account[4] - R - stake::Config account, carries warmup, cooldown, and slashing configuration.
StakeInstruction::Authorize(Pubkey, StakeAuthorize)
Updates the account with a new authorized staker or withdrawer, according to the StakeAuthorize parameter (Staker or Withdrawer). The transaction must be by signed by the Stakee account's current authorized_staker or authorized_withdrawer. Any stake lock-up must have expired, or the lock-up custodian must also sign the transaction.
- account[0] - RW - The StakeState.
StakeState::authorized_staker or authorized_withdrawer is set to to Pubkey.
StakeInstruction::Deactivate
A staker may wish to withdraw from the network. To do so he must first deactivate his stake, and wait for cooldown. The transaction must be signed by the stake's authorized_staker.
- account[0] - RW - The StakeState::Stake instance that is deactivating.
- account[1] - R - sysvar::clock account from the Bank that carries current epoch.
StakeState::Stake::deactivated is set to the current epoch + cooldown. The account's stake will ramp down to zero by that epoch, and Account::lamports will be available for withdrawal.
StakeInstruction::Withdraw(u64)
Lamports build up over time in a Stake account and any excess over activated stake can be withdrawn. The transaction must be signed by the stake's authorized_withdrawer.
- account[0] - RW - The StakeState::Stake from which to withdraw.
- account[1] - RW - Account that should be credited with the withdrawn lamports.
- account[2] - R - sysvar::clock account from the Bank that carries current epoch, to calculate stake.
- account[3] - R - sysvar::stake_history account from the Bank that carries stake warmup/cooldown history.
Benefits of the design
- Single vote for all the stakers.
- Clearing of the credit variable is not necessary for claiming rewards.
- Each delegated stake can claim its rewards independently.
- Commission for the work is deposited when a reward is claimed by the delegated stake.
Example Callflow
Staking Rewards
The specific mechanics and rules of the validator rewards regime is outlined here. Rewards are earned by delegating stake to a validator that is voting correctly. Voting incorrectly exposes that validator's stakes to slashing.
Basics
The network pays rewards from a portion of network inflation. The number of lamports available to pay rewards for an epoch is fixed and must be evenly divided among all staked nodes according to their relative stake weight and participation. The weighting unit is called a point.
Rewards for an epoch are not available until the end of that epoch.
At the end of each epoch, the total number of points earned during the epoch is summed and used to divide the rewards portion of epoch inflation to arrive at a point value. This value is recorded in the bank in a sysvar that maps epochs to point values.
During redemption, the stake program counts the points earned by the stake for each epoch, multiplies that by the epoch's point value, and transfers lamports in that amount from a rewards account into the stake and vote accounts according to the vote account's commission setting.
Economics
Point value for an epoch depends on aggregate network participation. If participation in an epoch drops off, point values are higher for those that do participate.
Earning credits
Validators earn one vote credit for every correct vote that exceeds maximum lockout, i.e. every time the validator's vote account retires a slot from its lockout list, making that vote a root for the node.
Stakers who have delegated to that validator earn points in proportion to their stake. Points earned is the product of vote credits and stake.
Stake warmup, cooldown, withdrawal
Stakes, once delegated, do not become effective immediately. They must first pass through a warmup period. During this period some portion of the stake is considered "effective", the rest is considered "activating". Changes occur on epoch boundaries.
The stake program limits the rate of change to total network stake, reflected in the stake program's config::warmup_rate (set to 25% per epoch in the current implementation).
The amount of stake that can be warmed up each epoch is a function of the previous epoch's total effective stake, total activating stake, and the stake program's configured warmup rate.
Cooldown works the same way. Once a stake is deactivated, some part of it is considered "effective", and also "deactivating". As the stake cools down, it continues to earn rewards and be exposed to slashing, but it also becomes available for withdrawal.
Bootstrap stakes are not subject to warmup.
Rewards are paid against the "effective" portion of the stake for that epoch.
Warmup example
Consider the situation of a single stake of 1,000 activated at epoch N, with network warmup rate of 20%, and a quiescent total network stake at epoch N of 2,000.
At epoch N+1, the amount available to be activated for the network is 400 (20% of 2000), and at epoch N, this example stake is the only stake activating, and so is entitled to all of the warmup room available.
epoch | effective | activating | total effective | total activating |
|---|---|---|---|---|
N-1 |
|
| 2,000 | 0 |
N | 0 | 1,000 | 2,000 | 1,000 |
N+1 | 400 | 600 | 2,400 | 600 |
N+2 | 880 | 120 | 2,880 | 120 |
N+3 | 1000 | 0 | 3,000 | 0 |
Were 2 stakes (X and Y) to activate at epoch N, they would be awarded a portion of the 20% in proportion to their stakes. At each epoch effective and activating for each stake is a function of the previous epoch's state.
epoch | X eff | X act | Y eff | Y act | total effective | total activating |
|---|---|---|---|---|---|---|
N-1 |
|
|
|
| 2,000 | 0 |
N | 0 | 1,000 | 0 | 200 | 2,000 | 1,200 |
N+1 | 333 | 667 | 67 | 133 | 2,400 | 800 |
N+2 | 733 | 267 | 146 | 54 | 2,880 | 321 |
N+3 | 1000 | 0 | 200 | 0 | 3,200 | 0 |
Withdrawal
Only lamports in excess of effective+activating stake may be withdrawn at any time. This means that during warmup, effectively no stake can be withdrawn. During cooldown, any tokens in excess of effective stake may be withdrawn (activating == 0). Because earned rewards are automatically added to stake, withdrawal is generally only possible after deactivation.
Lock-up
Stake accounts support the notion of lock-up, wherein the stake account balance is unavailable for withdrawal until a specified time. Lock-up is specified as an epoch height, i.e. the minimum epoch height that must be reached by the network before the stake account balance is available for withdrawal, unless the transaction is also signed by a specified custodian. This information is gathered when the stake account is created, and stored in the Lockup field of the stake account's state. Changing the authorized staker or withdrawer is also subject to lock-up, as such an operation is effectively a transfer.
Anatomy of a Validator
Pipelining
The validators make extensive use of an optimization common in CPU design, called pipelining. Pipelining is the right tool for the job when there's a stream of input data that needs to be processed by a sequence of steps, and there's different hardware responsible for each. The quintessential example is using a washer and dryer to wash/dry/fold several loads of laundry. Washing must occur before drying and drying before folding, but each of the three operations is performed by a separate unit. To maximize efficiency, one creates a pipeline of stages. We'll call the washer one stage, the dryer another, and the folding process a third. To run the pipeline, one adds a second load of laundry to the washer just after the first load is added to the dryer. Likewise, the third load is added to the washer after the second is in the dryer and the first is being folded. In this way, one can make progress on three loads of laundry simultaneously. Given infinite loads, the pipeline will consistently complete a load at the rate of the slowest stage in the pipeline.
Pipelining in the Validator
The validator contains two pipelined processes, one used in leader mode called the TPU and one used in validator mode called the TVU. In both cases, the hardware being pipelined is the same, the network input, the GPU cards, the CPU cores, writes to disk, and the network output. What it does with that hardware is different. The TPU exists to create ledger entries whereas the TVU exists to validate them.
TPU
TPU Block Diagram

TVU
TVU Block Diagram

Retransmit Stage
Retransmit Block Diagram

Blockstore
After a block reaches finality, all blocks from that one on down to the genesis block form a linear chain with the familiar name blockchain. Until that point, however, the validator must maintain all potentially valid chains, called forks. The process by which forks naturally form as a result of leader rotation is described in fork generation. The blockstore data structure described here is how a validator copes with those forks until blocks are finalized.
The blockstore allows a validator to record every shred it observes on the network, in any order, as long as the shred is signed by the expected leader for a given slot.
Shreds are moved to a fork-able key space the tuple of leader slot + shred index (within the slot). This permits the skip-list structure of the Exzo Network protocol to be stored in its entirety, without a-priori choosing which fork to follow, which Entries to persist or when to persist them.
Repair requests for recent shreds are served out of RAM or recent files and out of deeper storage for less recent shreds, as implemented by the store backing Blockstore.
Functionalities of Blockstore
- Persistence: the Blockstore lives in the front of the nodes verification pipeline, right behind network receive and signature verification. If the shred received is consistent with the leader schedule (i.e. was signed by the leader for the indicated slot), it is immediately stored.
- Repair: repair is the same as window repair above, but able to serve any shred that's been received. Blockstore stores shreds with signatures, preserving the chain of origination.
- Forks: Blockstore supports random access of shreds, so can support a validator's need to rollback and replay from a Bank checkpoint.
- Restart: with proper pruning/culling, the Blockstore can be replayed by ordered enumeration of entries from slot 0. The logic of the replay stage (i.e. dealing with forks) will have to be used for the most recent entries in the Blockstore.
Blockstore Design
- Entries in the Blockstore are stored as key-value pairs, where the key is the concatenated slot index and shred index for an entry, and the value is the entry data. Note shred indexes are zero-based for each slot (i.e. they're slot-relative).
- The Blockstore maintains metadata for each slot, in the SlotMeta struct containing:
- slot_index - The index of this slot
- num_blocks - The number of blocks in the slot (used for chaining to a previous slot)
- consumed - The highest shred index n, such that for all m < n, there exists a shred in this slot with shred index equal to n (i.e. the highest consecutive shred index).
- received - The highest received shred index for the slot
- next_slots - A list of future slots this slot could chain to. Used when rebuilding
the ledger to find possible fork points.
-
last_index - The index of the shred that is flagged as the last shred for this slot. This flag on a shred will be set by the leader for a slot when they are transmitting the last shred for a slot.
-
is_rooted - True iff every block from 0...slot forms a full sequence without any holes. We can derive is_rooted for each slot with the following rules. Let slot(n) be the slot with index n, and slot(n).is_full() is true if the slot with index n has all the ticks expected for that slot. Let is_rooted(n) be the statement that "the slot(n).is_rooted is true". Then:
is_rooted(0) is_rooted(n+1) iff (is_rooted(n) and slot(n).is_full()
- Chaining - When a shred for a new slot x arrives, we check the number of blocks (num_blocks) for that new slot (this information is encoded in the shred). We then know that this new slot chains to slot x - num_blocks.
- Subscriptions - The Blockstore records a set of slots that have been "subscribed" to. This means entries that chain to these slots will be sent on the Blockstore channel for consumption by the ReplayStage. See the Blockstore APIs for details.
- Update notifications - The Blockstore notifies listeners when slot(n).is_rooted is flipped from false to true for any n.
Blockstore APIs
The Blockstore offers a subscription based API that ReplayStage uses to ask for entries it's interested in. The entries will be sent on a channel exposed by the Blockstore. These subscription API's are as follows: 1. fn get_slots_since(slot_indexes: &[u64]) -> Vec<SlotMeta>: Returns new slots connecting to any element of the list slot_indexes.
- fn get_slot_entries(slot_index: u64, entry_start_index: usize,
max_entries: Option<u64>) -> Vec<Entry>:Returns the entry vector for the slot starting with entry_start_index, capping the result at max if max_entries == Some(max), otherwise, no upper limit on the length of the return vector is imposed.
Note: Cumulatively, this means that the replay stage will now have to know when a slot is finished, and subscribe to the next slot it's interested in to get the next set of entries. Previously, the burden of chaining slots fell on the Blockstore.
Interfacing with Bank
The bank exposes to replay stage:
- prev_hash: which PoH chain it's working on as indicated by the hash of the last
entry it processed
- tick_height: the ticks in the PoH chain currently being verified by this
bank
- votes: a stack of records that contain: 1. prev_hashes: what anything after this vote must chain to in PoH 2. tick_height: the tick height at which this vote was cast 3. lockout period: how long a chain must be observed to be in the ledger to
be able to be chained below this vote
Replay stage uses Blockstore APIs to find the longest chain of entries it can hang off a previous vote. If that chain of entries does not hang off the latest vote, the replay stage rolls back the bank to that vote and replays the chain from there.
Pruning Blockstore
Once Blockstore entries are old enough, representing all the possible forks becomes less useful, perhaps even problematic for replay upon restart. Once a validator's votes have reached max lockout, however, any Blockstore contents that are not on the PoH chain for that vote for can be pruned, expunged.
Gossip Service
The Gossip Service acts as a gateway to nodes in the control plane. Validators use the service to ensure information is available to all other nodes in a cluster. The service broadcasts information using a gossip protocol.
Gossip Overview
Nodes continuously share signed data objects among themselves in order to manage a cluster. For example, they share their contact information, ledger height, and votes.
Every tenth of a second, each node sends a "push" message and/or a "pull" message. Push and pull messages may elicit responses, and push messages may be forwarded on to others in the cluster.
Gossip runs on a well-known UDP/IP port or a port in a well-known range. Once a cluster is bootstrapped, nodes advertise to each other where to find their gossip endpoint (a socket address).
Gossip Records
Records shared over gossip are arbitrary, but signed and versioned (with a timestamp) as needed to make sense to the node receiving them. If a node receives two records from the same source, it updates its own copy with the record with the most recent timestamp.
Gossip Service Interface
Push Message
A node sends a push message to tells the cluster it has information to share. Nodes send push messages to PUSH_FANOUT push peers.
Upon receiving a push message, a node examines the message for:
- Duplication: if the message has been seen before, the node drops the message and may respond with
PushMessagePruneif forwarded from a low staked node - New data: if the message is new to the node
- Stores the new information with an updated version in its cluster info and purges any previous older value
- Stores the message in pushed_once (used for detecting duplicates, purged after
PUSH_MSG_TIMEOUT* 5 ms) - Retransmits the messages to its own push peers
- Expiration: nodes drop push messages that are older than
PUSH_MSG_TIMEOUT
Push Peers, Prune Message
A nodes selects its push peers at random from the active set of known peers. The node keeps this selection for a relatively long time. When a prune message is received, the node drops the push peer that sent the prune. Prune is an indication that there is another, higher stake weighted path to that node than direct push.
The set of push peers is kept fresh by rotating a new node into the set every PUSH_MSG_TIMEOUT/2 milliseconds.
Pull Message
A node sends a pull message to ask the cluster if there is any new information. A pull message is sent to a single peer at random and comprises a Bloom filter that represents things it already has. A node receiving a pull message iterates over its values and constructs a pull response of things that miss the filter and would fit in a message.
A node constructs the pull Bloom filter by iterating over current values and recently purged values.
A node handles items in a pull response the same way it handles new data in a push message.
Purging
Nodes retain prior versions of values (those updated by a pull or push) and expired values (those older than GOSSIP_PULL_CRDS_TIMEOUT_MS) in purged_values (things I recently had). Nodes purge purged_values that are older than 5 * GOSSIP_PULL_CRDS_TIMEOUT_MS.
Eclipse Attacks
An eclipse attack is an attempt to take over the set of node connections with adversarial endpoints.
This is relevant to our implementation in the following ways.
- Pull messages select a random node from the network. An eclipse attack on pull would require an attacker to influence the random selection in such a way that only adversarial nodes are selected for pull.
- Push messages maintain an active set of nodes and select a random fanout for every push message. An eclipse attack on push would influence the active set selection, or the random fanout selection.
Time and Stake based weights
Weights are calculated based on time since last picked and the natural log of the stake weight.
Taking the ln of the stake weight allows giving all nodes a fairer chance of network coverage in a reasonable amount of time. It helps normalize the large possible stake weight differences between nodes. This way a node with low stake weight, compared to a node with large stake weight will only have to wait a few multiples of ln(stake) seconds before it gets picked.
There is no way for an adversary to influence these parameters.
Pull Message
A node is selected as a pull target based on the weights described above.
Push Message
A prune message can only remove an adversary from a potential connection.
Just like pull message, nodes are selected into the active set based on weights.
Notable differences from PlumTree
The active push protocol described here is based on Plum Tree. The main differences are:
- Push messages have a wallclock that is signed by the originator. Once the wallclock expires the message is dropped. A hop limit is difficult to implement in an adversarial setting.
- Lazy Push is not implemented because its not obvious how to prevent an adversary from forging the message fingerprint. A naive approach would allow an adversary to be prioritized for pull based on their input.
The Runtime
The runtime is a concurrent transaction processor. Transactions specify their data dependencies upfront and dynamic memory allocation is explicit. By separating program code from the state it operates on, the runtime is able to choreograph concurrent access. Transactions accessing only read-only accounts are executed in parallel whereas transactions accessing writable accounts are serialized. The runtime interacts with the program through an entrypoint with a well-defined interface. The data stored in an account is an opaque type, an array of bytes. The program has full control over its contents.
The transaction structure specifies a list of public keys and signatures for those keys and a sequential list of instructions that will operate over the states associated with the account keys. For the transaction to be committed all the instructions must execute successfully; if any abort the whole transaction fails to commit.
Account Structure
Accounts maintain a lamport balance and program-specific memory.
Transaction Engine
The engine maps public keys to accounts and routes them to the program's entrypoint.
Execution
Transactions are batched and processed in a pipeline. The TPU and TVU follow a slightly different path. The TPU runtime ensures that PoH record occurs before memory is committed.
The TVU runtime ensures that PoH verification occurs before the runtime processes any transactions.
At the execute stage, the loaded accounts have no data dependencies, so all the programs can be executed in parallel.
The runtime enforces the following rules:
- Only the owner program may modify the contents of an account. This means that upon assignment data vector is guaranteed to be zero.
- Total balances on all the accounts is equal before and after execution of a transaction.
- After the transaction is executed, balances of read-only accounts must be equal to the balances before the transaction.
- All instructions in the transaction executed atomically. If one fails, all account modifications are discarded.
Execution of the program involves mapping the program's public key to an entrypoint which takes a pointer to the transaction, and an array of loaded accounts.
SystemProgram Interface
CreateAccount- This allows the user to create an account with an allocated data array and assign it to a Program.CreateAccountWithSeed- Same asCreateAccount, but the new account's address is derived from- the funding account's pubkey,
- a mnemonic string (seed), and
- the pubkey of the Program
Assign- Allows the user to assign an existing account to a program.Transfer- Transfers lamports between accounts.
Program State Security
For blockchain to function correctly, the program code must be resilient to user inputs. That is why in this design the program specific code is the only code that can change the state of the data byte array in the Accounts that are assigned to it. It is also the reason why Assign or CreateAccount must zero out the data. Otherwise there would be no possible way for the program to distinguish the recently assigned account data from a natively generated state transition without some additional metadata from the runtime to indicate that this memory is assigned instead of natively generated.
To pass messages between programs, the receiving program must accept the message and copy the state over. But in practice a copy isn't needed and is undesirable. The receiving program can read the state belonging to other Accounts without copying it, and during the read it has a guarantee of the sender program's state.
Notes
- There is no dynamic memory allocation. Client's need to use
CreateAccountinstructions to create memory before passing it to another program. This instruction can be composed into a single transaction with the call to the program itself. CreateAccountandAssignguarantee that when account is assigned to the program, the Account's data is zero initialized.- Transactions that assign an account to a program or allocate space must be signed by the Account address' private key unless the Account is being created by
CreateAccountWithSeed, in which case there is no corresponding private key for the account's address/pubkey. - Once assigned to program an Account cannot be reassigned.
- Runtime guarantees that a program's code is the only code that can modify Account data that the Account is assigned to.
- Runtime guarantees that the program can only spend lamports that are in accounts that are assigned to it.
- Runtime guarantees the balances belonging to accounts are balanced before and after the transaction.
- Runtime guarantees that instructions all executed successfully when a transaction is committed.
Future Work
- Continuations and Signals for long running Transactions